QQ 空间爬虫之爬取说说
今天来讲获取说说~
为什么把获取说说放在后面讲呢,主要是说说的结构相对来说复杂一点,跟留言不一样,它包括三层结构,一是说说内容本身,二是说说的评论以及回复,第三就是这条说说获得的赞同数,从空间的角度来看可能这三者结合地很好,层次关系和赞同关系一目了然,但是我们从接口获取到的数据并非如此,一层一层来看。
接口地址
所有说说
首先还是数据的接口地址。方法还是和上篇获取留言一样,从控制台查看请求,从返回的json数据着手处理。 说说的接口地址如下:
https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6?uin=目标qq&pos=起始位置&num=10&format=jsonp&g_tk=g_tk值
url本身就不分析了,和留言的相似,也是需要循环得到所有说说。
详细信息
之所以强调所有说说,是因为在这里我们可以只取tid值,这是说说的唯一标识,对于每一条具体的说说还有一个更详细的接口:
https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msgdetail_v6?uin=目标qq&tid=说说id&format=jsonp&g_tk=g_tk值
可以看到这是一个detail的接口,返回的就是更详细的说说信息,由于太长了就不截图了,可以自己打开看一下。这个地址的关键参数便是刚刚提到的tid,把tid传过来,根据这个tid和发布者,以及登录的g_tk值,就能得到一条说说包括评论在内的详细信息。
点赞情况
上面两个地址能够得到所有说说以及每一条说说的详细内容,但还少了点东西,就是点赞数。上面两个接口的返回数据都没有点赞情况对应的数据,一开始也有点纳闷,这应该是在一个整体里面的,但看了好多遍,确实是没有。后来点了几次xx等x人觉得很赞,从请求里看到点赞情况是有另外一个接口的:
https://h5.qzone.qq.com/proxy/domain/users.qzone.qq.com/cgi-bin/likes/get_like_list_app?uin=目标qq&unikey=unikey&begin_uin=0&query_count=60&if_first_page=1&g_tk=g_tk值
其中unikey是这条说说的地址:
http://user.qzone.qq.com/目标qq/mood/说说id
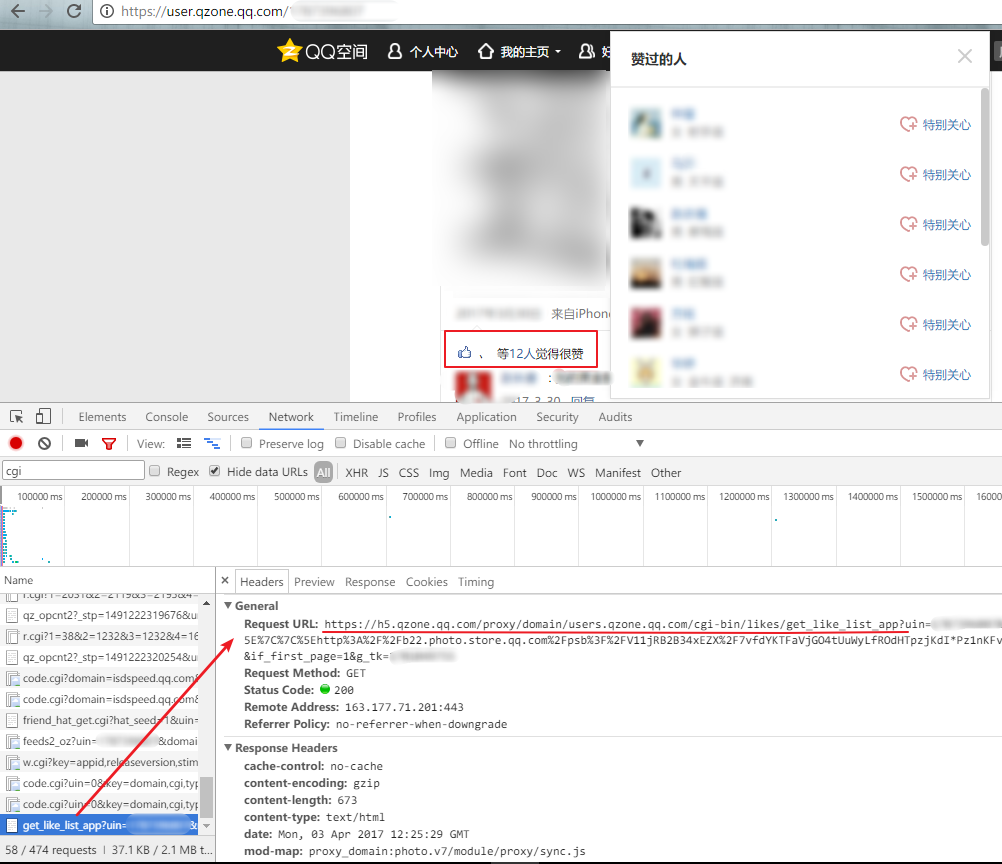
403,所以若非必要,点赞部分不爬取也是可以的…或者想一个避免403的方法,比如sleep,可这肯定会使整个程序慢下来,毕竟不敢贸然上多线程…
一个小Tips: 点赞数据的获取是不一定要有好友关系的,也就是说可以用小号对赞同数另外爬取,避免被封号…不是真正的封号,只是无法再访问这个地址了,一般是一天,泪的教训…
通过上面第一个地址,可以得到一个好友的所有说说的tid,根据每个tid去获取它的详细内容和点赞情况,这样就能把所有说说爬下来了~
数据分析
前面提到过了,说说和留言不一样,它除了内容本身,还有下面的评论,以及在评论下面的回复,它可能是互动双方,也有可能是第三个好友的回复(留言下面只能是双方的互动),最后还有点赞的好友的情况
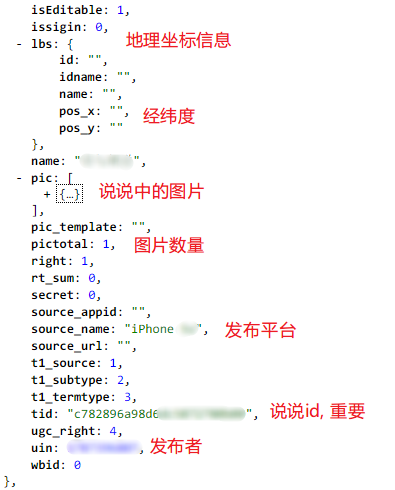
分析一下返回的数据,这是说说内容和评论内容,图片太长分两次截吧

点赞的情况如下,乱码是因为网站本身的问题

数据库设计
刚才提到了,说说的结构相对复杂,考虑到一张表无法将所有字段包括进去,于是设计了三张表,分别是说说内容表,评论及回复表,点赞表
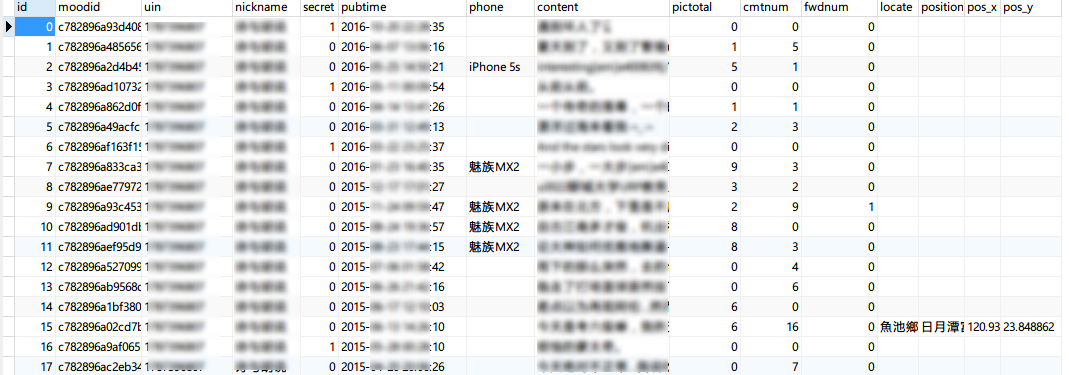
说说表qq_moods
create_tb_sql = 'CREATE TABLE IF NOT EXISTS %s\
(id int primary key, \
moodid varchar(30), \ #说说id
uin varchar(15), \ #发布者
nickname varchar(50), \ #发布者昵称
secret int(2), \ #有时候qq签名会同步为说说,设置为仅自己可见时该字段为1
pubtime varchar(20), \ #发布时间
phone varchar(30), \ #发布平台
content TEXT, \ #说说内容,注意TEXT
pictotal int(4), \ #图片总数
cmtnum int(4), \ #评论总数
fwdnum int(4), \ #转发总数
locate varchar(50), \ #地理位置
position varchar(50), \
pos_x varchar(20), \ #经纬度
pos_y varchar(20))' % tablename
效果如下
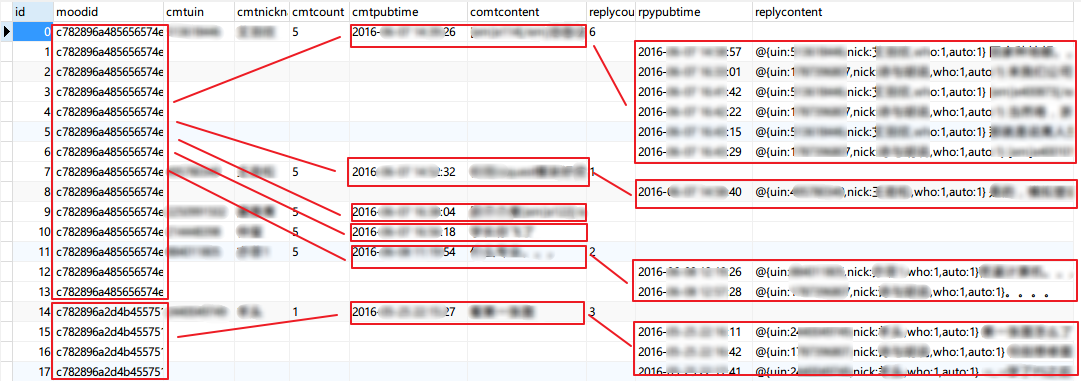
评论表qq_moods_reply
create_tb_sql = 'CREATE TABLE IF NOT EXISTS %s\
(id int primary key, \
moodid varchar(30), \ #说说id
cmtuin varchar(15), \ #评论者
cmtnickname varchar(80), \ #评论者昵称
cmtcount varchar(4), \ #该说说评论数
cmtpubtime varchar(20), \ #评论发布时间
comtcontent TEXT, \ #评论内容
replycount varchar(4), \ #该评论下的回复数
rpypubtime varchar(20), \ #回复发布时间
replycontent TEXT \ #回复内容
)' % tablename
可能有人会问,这怎么表示评论和回复之间的层次关系呢?不急,我们先来看一下效果
点赞表qq_moods_like
create_tb_sql = 'CREATE TABLE IF NOT EXISTS %s\
(id int primary key, \
moodid varchar(30), \ #说说id
likecount varchar(6), \ #点赞总数
uin varchar(15), \ #点赞者
nickname varchar(50), \ #昵称
gender varchar(4), \ #性别
constellation varchar(10), \ #星座
addr varchar(10), \ #城市
if_qq_friend int(2), \ #是否是好友
if_special_care int(2) \ #是否特别关心
)' % tablename
效果如下
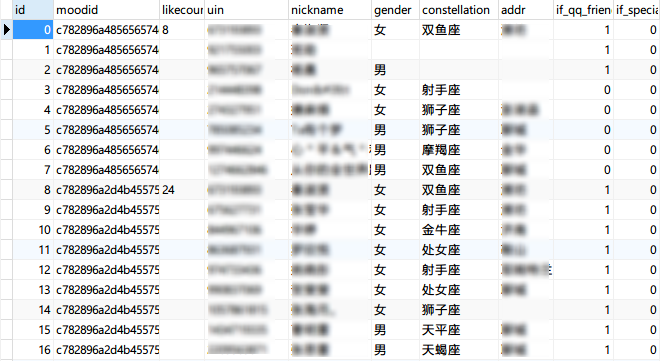
同样的,同一说说的点赞适当插入空值可以表现出层次关系
核心代码
考虑到数据解析本身难度并不大,但爬取的逻辑还是挺重要的,所以这里贴一部分关键的代码
while True:
url = 'https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6?uin='+ target_qq + '&pos=' + str(self.moodstatus['moodPos']) + '&num=10&format=jsonp&g_tk=' + g_tk
r = s.get(url, headers = header)
dict = self.data2json(r.content[10:-2].strip().replace('\n',''))
if self.moodstatus['moodPos'] < dict['usrinfo']['msgnum'] - 1: #get 10 items at a time
self.moodstatus['moodPos'] += 10
print 'current qq: %s, current pos: %s' % (target_qq, str(self.moodstatus['moodPos']))
else:
break
if dict['msglist'] == None:
print u'\n之前动态被封存,无法获取.'
break
for item in dict['msglist']:
print 'get moodId: %s, moods tid: %s' % (self.moodstatus['moodId'], item['tid'])
url = 'https://h5.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msgdetail_v6?uin='+ target_qq + '&tid='+ item['tid'] + '&format=jsonp&g_tk=' + g_tk
r = s.get(url, headers = header)
data = self.data2json(r.content[10:-2].strip().replace('\n','').replace('\\',''))
self.operate_db_moods(db, 'qq_moods', data) #get moods details
if item.has_key('commentlist'):
self.operate_db_moods_reply(db, 'qq_moods_reply', data) #get moods reply
self.get_moods_like(qq, target_qq, cookie, item['tid'], db) #get moods like
解释
moodstatus是用来存放当前爬虫的状态的,便于程序意外中断后断点续爬。关于如何保存状态,如果有需要的话单独拿出来讲,这里只要关心这个moodstatus包含的键值对就好了。is_last_mood用来标识是否爬到了最后一条说说,下次爬取只要检测这个值就能判断是否继续了。self.moodstatus = {"moodTid": '', "is_last_mood": 0, "moodPos": 0, "moodId": 0, "moodcmtId": 0, "moodlikeId": 0}data2json(data)是将request获取的内容转换为json对象def data2json(self, data): json_obj = json.loads(data.decode('utf-8')) return json_objoperate_db*(self, db, tablename, data)方法是用来操作数据库的,有建表和插入数据的实现
流程图
画了一个简单的流程图
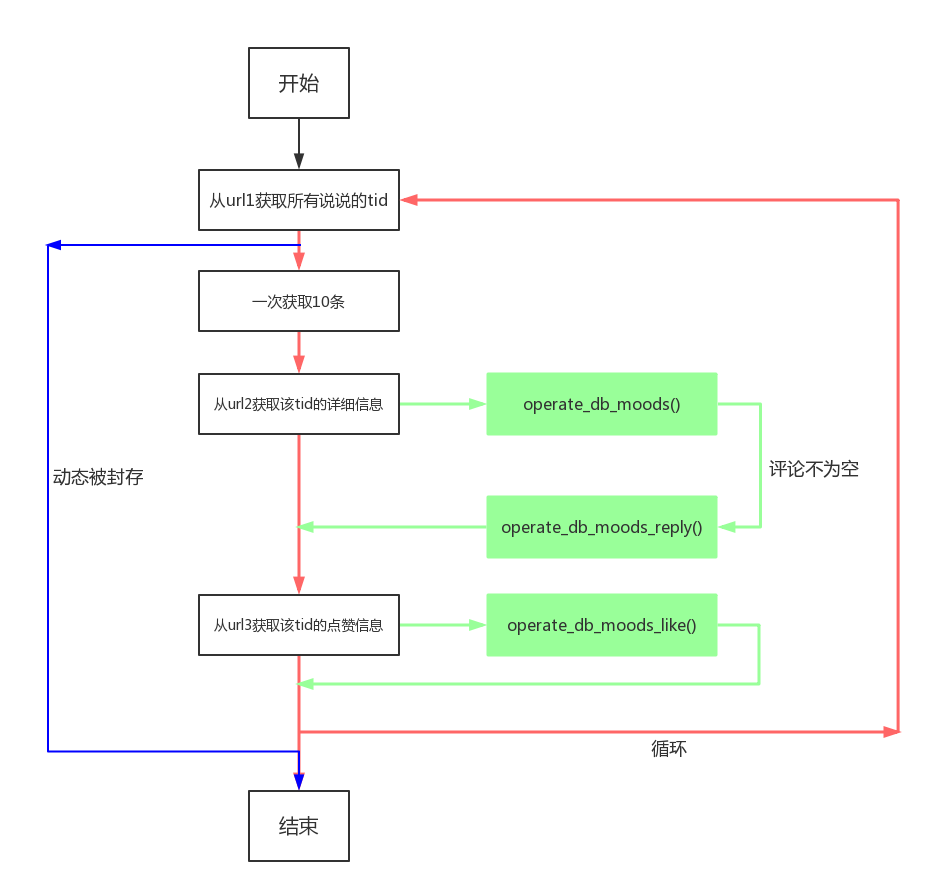
结束语
说说部分的代码比其他复杂一些,主要是信息相对较多,数据之间的关系也相对复杂,除了常规边界判断,特殊字符等,还要注意如何正确表示层次关系,以及爬虫状态的保存(谁也不想爬了几千条中断了然后重新开始爬= =)
分享一条查询Top 20评论数的sql语句,对于说说表,留言表也是是用的
SELECT cmtnickname, count(cmtnickname) AS count FROM qq_moods_reply WHERE cmtnickname != '' GROUP BY cmtnickname ORDER BY count DESC LIMIT 20